
Détection de Contrefaçons et Marché Gris sur les Plateformes Sociales et de Seconde Main
Les plateformes de seconde main et les réseaux sociaux ; Vinted, Leboncoin, Facebook Marketplace, sont devenus des terrains privilégiés pour les contrefacteurs. Dans le secteur du luxe, on parle d’un manque à gagner estimé à près de 15 milliards d’euros par an, et les volumes d’annonces rendent tout contrôle manuel impossible.
Pour un grand retailer ou une maison de mode, le sujet est stratégique :
- Les contrefaçons dégradent l’image de marque en circulant sous le même nom.
- Elles diluents la valeur perçue et brouillent le positionnement prix.
- Elles créent un manque à gagner direct et entament la confiance des consommateurs.
L’objectif de cette extension est d’exploiter la similarité visuelle pour repérer automatiquement des annonces potentiellement contrefaisantes sur des sites comme Vinted, Leboncoin ou Facebook Marketplace. Ces plateformes comptent des millions d’annonces et sont de plus en plus ciblées par les contrefacteurs – par exemple, dans le secteur du luxe le manque à gagner atteint environ 15 milliards d’euros par an[1]. Déjà, il est recommandé aux acheteurs d’utiliser la recherche par image inversée (Google Lens, etc.) pour vérifier qu’un article vintage n’existe pas ailleurs à bas prix[2].
Nous proposons d’automatiser ce principe à grande échelle : les photos des annonces sont extraites puis comparées, via un modèle visuel avancé, aux dessins industriels et visuels authentiques. Le système identifie ainsi les annonces présentant une similarité forte avec un modèle protégé. Cette détection rapide permet d’alerter immédiatement les titulaires de droits ou les autorités, en analysant en temps réel des flux massifs d’annonces pour accélérer les procédures de retrait[3][2].
Méthodologie proposée
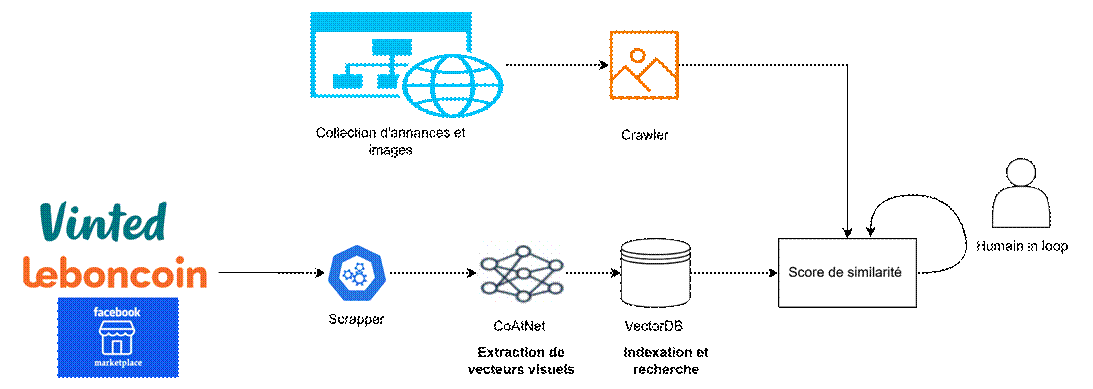
Exemple de page d’annonce Vinted montrant plusieurs articles mis en vente par un utilisateur. La collecte des images commence par un agent logiciel (crawler) qui parcourt les annonces publiques de Vinted, Leboncoin ou Facebook Marketplace. Selon la plateforme, on utilise une API dédiée ou un scraping respectueux des conditions d’utilisation pour télécharger les photos du produit et récupérer les métadonnées associées (titre, description, marque déclarée, prix, etc.). Chaque photo extraite est alors traitée par le modèle CoAtNet (pré-entraîné en vision) pour en obtenir un vecteur de caractéristiques. Ce vecteur hautement dimensionnel est comparé aux vecteurs des dessins industriels enregistrés dans la base de données existante : on enrichit ainsi l’index FAISS en y ajoutant à la fois les vecteurs des photos extraites et ceux des dessins protégés de référence[4]. La recherche de similarité s’effectue ensuite grâce à FAISS, qui permet de rechercher efficacement parmi des millions de vecteurs[4]. En pratique, on calcule la similarité entre chaque vecteur d’annonce et l’ensemble des vecteurs de dessins ; si le score dépasse un seuil prédéfini, l’annonce est marquée comme suspecte. Pour augmenter la fiabilité, on combine ce score visuel avec les données textuelles : par exemple, on peut vérifier la cohérence entre la marque détectée et la base de dessins du même titulaire.
La méthodologie s’articule en plusieurs étapes clés :
- Collecte des annonces. On utilise des scrapers ou des API pour extraire les données des plateformes ciblées (Leboncoin, Vinted, Facebook Marketplace, etc.). Par exemple, des outils comme Vinted-Scraper, Apify récupèrent images et métadonnées d’annonces pour stockage local[4]. Cette étape gère différents formats et encodings fournis par les sites.
- Prétraitement des images. Les images sont standardisées (format et taille uniformes) et normalisées (pixels mis à l’échelle) pour garantir une cohérence et une stabilité des données. Des filtres légers sont appliqués pour réduire le bruit et améliorer la qualité visuelle, renforçant ainsi la robustesse et l’efficacité de l’analyse par le réseau de neurones[5][6].
- Encodage des caractéristiques visuelles. Chaque image est passée dans un réseau de neurones profond pré-entraîné pour générer un vecteur d’embedding. Ce vecteur de grande dimension (p. ex. 512 ou 1024 valeurs) représente l’information visuelle sémantique de l’objet. L’usage de modèles performants comme CoAtNet peut être fine-tuné sur notre propre jeu de données. Cette adaptation permet d’optimiser la capacité du modèle à reconnaître les caractéristiques distinctives de nos produits cibles, tout en conservant la robustesse et la performance offertes par le modèle pré-entraîné[7].
- Calcul de la similarité. Les vecteurs générés sont comparés entre eux pour détecter les correspondances. On peut utiliser la distance cosinus (sur vecteurs normalisés) ou la distance euclidienne (L2) selon la stratégie de normalisation. Un seuil adaptatif de similarité est défini à partir de données de référence pour équilibrer taux de détection et fausses alertes. L’idée est de ne conserver que les paires d’annonces visuellement très proches (potentiellement le même design ou un plagiat) pour analyse complémentaire.
- Indexation vectorielle (FAISS). Les vecteurs extraits sont indexés dans une base de recherche efficace avec FAISS (Facebook AI Similarity Search)[9]. FAISS offre plusieurs modes : un IndexFlatL2 stocke tous les vecteurs pour une recherche exhaustive (exacte mais coûteuse)[10], tandis qu’un index approximatif (par exemple IVF, HNSW ou quantization) accélère les requêtes sur de très grands jeux de données avec un compromis précision/vitesse. On choisit selon la volumétrie (ex. faiss-cpu vs faiss-gpu pour accélération) et l’exactitude souhaitée. Chaque nouveau vecteur d’annonce est ajouté à l’index (avec un ID associé) pour permettre des recherches ultérieures rapides.
- Revue humaine (Human-in-the-loop). Le système produit pour chaque annonce un score de risque (basé sur la similarité avec des modèles connus ou d’autres annonces suspectes). On fixe un seuil de confiance : au‑dessous duquel l’annonce est écartée, et au‑dessus duquel elle est signalée pour examen humain. Les solutions d’IA fournissent souvent un score de confiance en pourcentage et orientent les flux de traitement (« straight-through » vs « human-in-loop »)[11]. En pratique, on peut viser, par exemple, à réorienter 5–10 % des annonces détectées vers un expert pour validation, afin de maximiser la précision (minimiser les faux positifs) tout en conservant un bon rappel des vraies fraudes. Ce réglage dépend de la politique de la plateforme : un seuil élevé privilégie la fiabilité (peu d’alertes, mais moins de détéctions), un seuil bas privilégie la couverture des fraudes (plus d’alertes à traiter). Un processus de feedback continu (ajustement des seuils via évaluation sur base d’exemples labellisés) complète ce workflow[11].
Agents intelligents et analyses avancées. Au‑delà du traitement unitaire d’annonces, on intègre des agents logiciels capables d’enrichir l’analyse de l’écosystème :
- Suggestion de classe Locarno. Un agent peut identifier automatiquement la catégorie Locarno du produit (par exemple « articles vestimentaires », « horlogerie », etc.) à partir de l’image et du texte. Cela facilite le classement des alertes et la comparabilité par type de produit. Par exemple, des modèles de classification d’images ou de mots-clés peuvent mapper un sac à main sur la Locarno « section 3 : Articles de maroquinerie », un tee-shirt sur « section 2 : Vêtements », etc. Ce pré-étiquetage assisté réduit la charge manuelle des examinateurs et améliore la cohérence du suivi.
- Décision autonome partielle – score multi-sources. Chaque annonce reçoit un score synthétisant plusieurs sources d’information (image visuelle, description textuelle, historique du vendeur, comparaisons avec la base de données produits authentiques de la marque, etc.). Un agent peut fusionner ces signaux : par exemple, compléter la recherche d’image par une recherche d’image par similarité dans une base officielles (à l’instar de l’outil OMPI de recherche d’images similaires sur la base mondiale des marques[13]) pour identifier des éléments identiques dans des catalogues connus. Si le score global dépasse un seuil, l’agent peut générer automatiquement une alerte (p.ex. cacher la publication ou notifier le titulaire de droit) ou assigner une priorité élevée dans la revue humaine. Ce scoring contextuel permet des actions en quasi-temps réel tout en laissant aux humains la décision finale critique.
Cette approche, inspirée des moteurs de recherche d’images, peut traiter de très grands volumes d’annonces en tirant parti de la rapidité de FAISS pour la recherche de similarité sur des millions de vecteurs[4].
Défis techniques et éthiques
Qualité et variabilité des images : les photos d’utilisateur sont hétérogènes (angles, arrière-plans, éclairage, résolution faible ou compressée). L’algorithme doit être robuste à ces variations. Une photo mal cadrée ou un reflet peuvent détériorer l’embedding visuel.
Images artificielles ou retouchées : certains vendeurs postent des clichés créés ou modifiés par IA (voir l’enquête TF1 sur des mannequins virtuels qui n’existent pas[6]). De tels visuels peuvent ne pas correspondre exactement à un produit réel, rendant l’algorithme moins fiable.
Limites contextuelles : L’IA est capable de mesurer la similarité visuelle entre des produits, mais elle ne dispose pas de la compréhension contextuelle nécessaire pour distinguer un usage licite d’un usage illicite. Ainsi, un article authentique provenant du marché parallèle ou de la seconde main peut présenter une forte proximité visuelle avec un design protégé sans relever pour autant de la contrefaçon. Comme le souligne Dreyfus, l’absence de perception des dynamiques de marché et du cadre juridique peut entraîner des alertes erronées[8]. Un expert humain reste nécessaire pour trancher.
Faux positifs et responsabilité : un design proche dans le style ou un produit inspiré (mais légal) peut déclencher une alerte injustifiée. Il faut donc calibrer finement le seuil de similarité et prévoir une phase de validation manuelle pour éviter de fausser les signalements.
Respect de la vie privée et du droit : les annonces comportent souvent des données personnelles (photos de vendeurs, informations de profil). Leur collecte et traitement massif posent des enjeux RGPD sérieux[9]. Il peut être nécessaire d’anonymiser ou d’obtenir un consentement implicite, car la jurisprudence considère que les images sur les réseaux restent protégées comme données personnelles ou œuvre de l’esprit. De plus, les responsabilités juridiques en cas d’erreur (faux positif) doivent être anticipées.
Perspectives et pistes de déploiement
Agents automatiques de veille : déployer des scripts ou bots qui parcourent en continu les nouvelles annonces (24/7). Ces agents extraient les images récentes et évaluent leur score de similarité dès leur publication, ne remontant que les cas suspects.
Analyse périodique en batch : en complément, programmer des scans récurrents (quotidien, hebdomadaire) sur l’ensemble du catalogue pour détecter des annonces plus anciennes. Cela permet de ne pas manquer des vendeurs récidivistes et d’ajuster les modèles en fonction des nouvelles tendances de contrefaçon.
Signalement semi-automatisé : mettre en place un tableau de bord ou une interface sécurisée pour les titulaires de droits et autorités. Les annonces suspectes détectées sont listées avec leur photo, score et métadonnées, prêtes à être examinées. Après validation humaine, l’outil peut générer des notifications de retrait ou de plainte (par exemple en automatisant la lettre de mise en demeure)[5].
Intégration réglementaire : anticiper les obligations légales à venir. Par exemple, l’« AI Act » européen imposera bientôt aux plateformes de signaler et d’étiqueter les images générées par IA[10]. Notre solution pourrait être proposée aux opérateurs (Vinted, LeBonCoin, etc.) comme module de conformité pour leur modération automatique. De même, le Règlement DSA encourage les outils proactifs de détection des contenus illicites, et ce système y contribue directement.
Amélioration continue du modèle : incorporer du feedback humain (annotations des cas réels) pour réentraîner et affiner les algorithmes. Une approche multimodale (combiner texte et image, par exemple via des modèles type CLIP) améliorerait la précision. On peut aussi enrichir l’analyse avec la reconnaissance optique de caractères (OCR) pour lire les logos/étiquettes sur les photos, ou analyser la langue des descriptions pour détecter des incohérences.
Par exemple, dans le cas d’une sac de luxe, le système est capable d’identifier automatiquement des différences extrêmement subtiles entre un modèle authentique et une copie — comme illustré ci-dessous — même lorsque le prix affiché semble cohérent. Cette capacité de détection fine permet de repérer rapidement une contrefaçon et d’empêcher les plateformes comme Vinted ou Leboncoin de laisser passer des annonces frauduleuses.

En résumé, l’adaptation de l’outil de similarité CoAtNet+FAISS à la surveillance des annonces en ligne offre une piste concrète pour renforcer la lutte anti-contrefaçon. Elle complète la veille humaine et profite aux titulaires de droits et aux autorités en leur fournissant une visibilité automatisée sur un marché devenu très opaque[3][1].
Sources : Articles récents sur la détection de la contrefaçon en ligne[1][3][2], documentation FAISS[4] et actualités sur les pratiques des contrefacteurs[7][9]. (Crédits image : TF1 Info)
[1] Contrefaçon et réseaux sociaux | Bruzzo Dubucq
https://bruzzodubucq.com/contrefacon-et-reseaux-sociaux/
[2] [6] [10] VÉRIF' - Fausses occasions, mais vraies tromperies : comment l'IA maquille de la fast-fashion en vintage | TF1 INFO
[3] [5] [8] Quelles limites à la détection de la contrefaçon en ligne par l’intelligence artificielle ? - dreyfus
[4] Faiss: A library for efficient similarity search - Engineering at Meta
[7] State of the Fake Report - 2024 | Entrupy
https://www.entrupy.com/report/state-of-the-fake-report-2024/
[9] AVIS JURIDIQUE – IA et web scraping : est-ce légal ?
https://www.solutions-numeriques.com/avis-juridique-ia-et-web-scraping-est-ce-legal/



